孙茂松 - 漫谈基于深度学习的中文计算
强调的一个概念是 中文自然语言处理需要加入专家知识。主要介绍的工作是 词表学习:
- 嵌入字信息的词表学习
实践中还是经常会用到的技巧;
词向量本身对高频词是没问题的,比如说取相近词 K 近邻,猪肉/鸡肉语义是相似的,但对低频词/新词像马肉/龙肉,语义相关性就不高了;
因此在词向量出现歧义时可以加入字向量,相当于平滑作用,在这个刻度上没有这种信息,就进行回退;
提到了一些其他 trick- Position-based character embeddings 区分字在词中出现的位置,也就是用 char+pos 来表示字,idea 是通常一个字可能出现在词的开始、中间、尾部(用 $c^B$, $c^M$, $c^E$ 表示),却分别代表不同的含义,如车道、人行道和道法、道经中的道就不是一个含义;
- Cluster-based character embeddings,对每个字的所有 occurrence 进行聚类,然后对每个类建一个 embedding
参考论文:Joint Learning of Character and Word Embeddings
- 嵌入中文资源,基于知网的词表学习
作用大概是消歧,利用 hownet 解决中文词语的多义性,类比 wordnet 用来加强英语的多义性学习一样
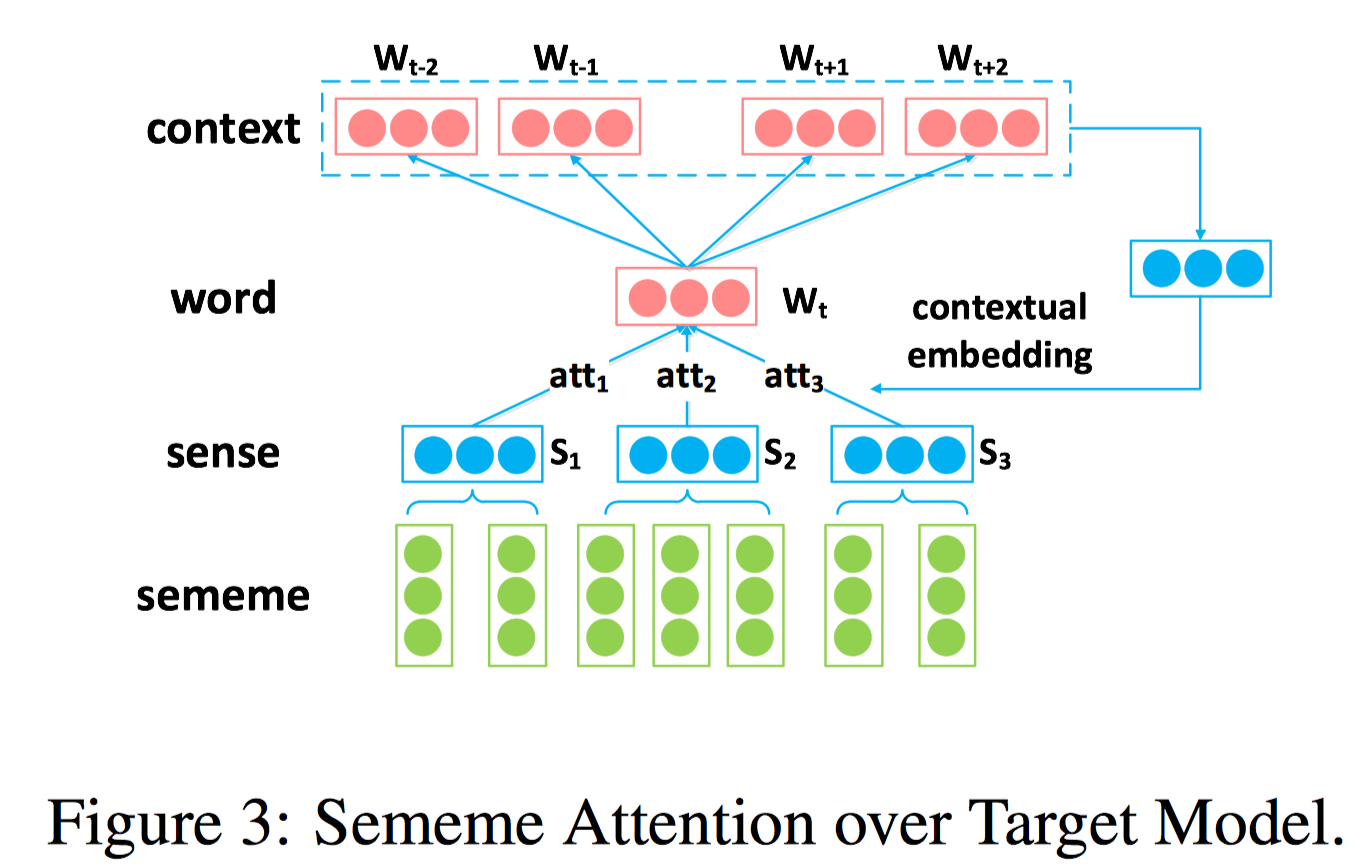
当然 HowNet 和 WordNet 的构造还是有很大不同的。HowNet 对十几万汉语常用词进行了描述,描述用的三要素分别是 sememe,sense 和 word,比如 apple 包含了两个 sense,sense1 是水果,sense2 是电脑,对每个 sense,sememe 可以描述其对应的属性,这些属性会通过相对复杂的层级结构来对目标 sense 进行说明。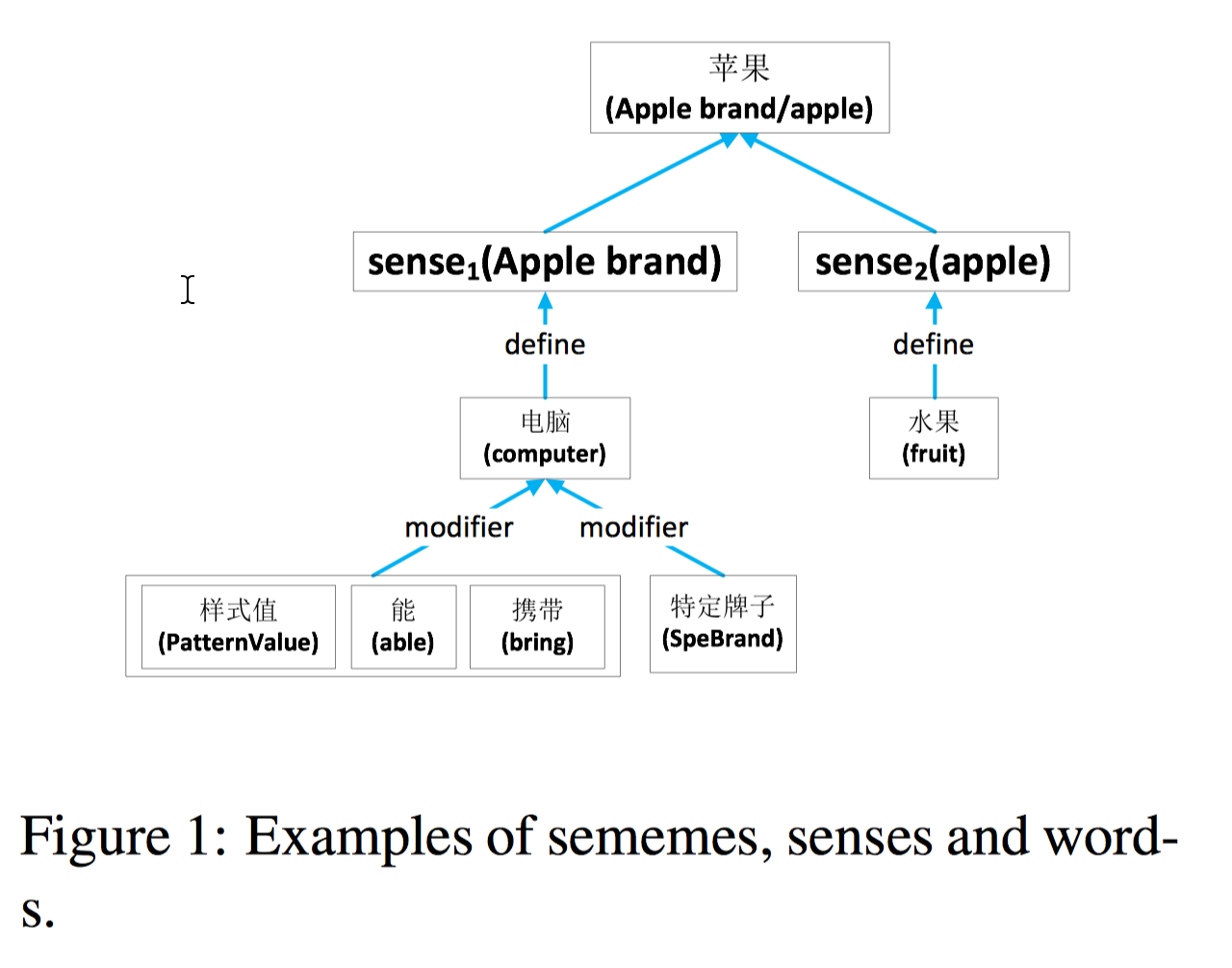 在基于 hownet 的词表学习里,sememe 是最小的语义单元,数量有限,大概两千个。每个单词可能对应多个 sense,将每个 sense 对应的 sememe 看成是一个集合,相似的 sense 会包含相同的 sememe。训练模型基于经典的 skip-gram,考虑上下文的同时,也考虑了词的 sememe 信息以及 sememe 与 sense 之间的关系。提供了三种融合方法,SSA/SAC/SAT,SSA 对每个 target word 取它对应所有 sememe embeddings 的平均值,SAC 对 context words 进行消歧来更好的学习目标单词,也就是 context 用 sememe embedding 来表示 ,target word embedding 可以看做是为 context word embedding 选择最合适的 sense 和 sememe 的一个 attention 机制,而 SAT 中 context 用原来的 embedding 表示,但 target word 用 sememe embedding 表示,把 context words 看做是 target word 不同 sense 上的 attention。
在基于 hownet 的词表学习里,sememe 是最小的语义单元,数量有限,大概两千个。每个单词可能对应多个 sense,将每个 sense 对应的 sememe 看成是一个集合,相似的 sense 会包含相同的 sememe。训练模型基于经典的 skip-gram,考虑上下文的同时,也考虑了词的 sememe 信息以及 sememe 与 sense 之间的关系。提供了三种融合方法,SSA/SAC/SAT,SSA 对每个 target word 取它对应所有 sememe embeddings 的平均值,SAC 对 context words 进行消歧来更好的学习目标单词,也就是 context 用 sememe embedding 来表示 ,target word embedding 可以看做是为 context word embedding 选择最合适的 sense 和 sememe 的一个 attention 机制,而 SAT 中 context 用原来的 embedding 表示,但 target word 用 sememe embedding 表示,把 context words 看做是 target word 不同 sense 上的 attention。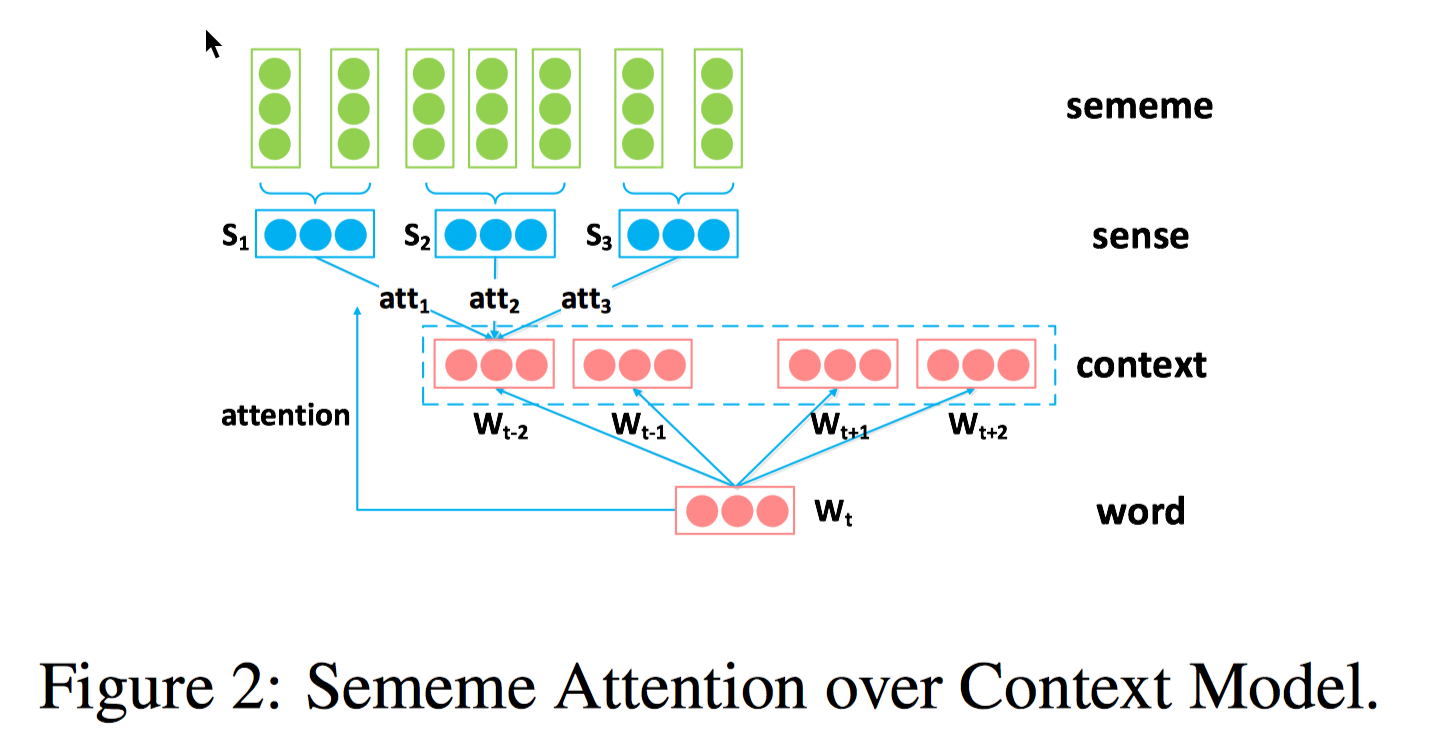
 基于 HowNet 的词表学习里,sememe, sense, word 之间能够互相打通。在对低频词和新词问题上,由于多了词与词之间共享的 sememe embeddings,低频词能够被解码成 sememe 并通过其他词得到良好的训练,相比于传统 WRL 模型能有更好的表现。
基于 HowNet 的词表学习里,sememe, sense, word 之间能够互相打通。在对低频词和新词问题上,由于多了词与词之间共享的 sememe embeddings,低频词能够被解码成 sememe 并通过其他词得到良好的训练,相比于传统 WRL 模型能有更好的表现。
参考论文:Improved Word Representation Learning with Sememes - 最后还介绍了清华出品的古诗系统,提到了要通过与情感结合、与知识图谱结合等方法来增强作诗系统。
赵军 - 开放域事件抽取
主要讲的还是关系抽取中的远程监督(Distant Supervision)问题。远程监督基本假设是“两个实体如果在知识库中存在某种关系,则包含该两个实体的非结构化句子均能表示出这种关系”,这样的假设太强,带来的问题是噪声很多,一个解决方案是引入多示例学习,假定至少有一个句子表示了这种关系而不是每个句子都表示这种关系,把最有可能的句子标注出来,以提高性能。介绍的 paper 是 Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks,EMNLP 2015 挺有名的一篇文章,用分段卷积神经网络 PCNN 来自动学习特征,以及加入 multi-instance learning 来解决远程监督引起的噪声问题。主要 idea 是在池化层通过两个实体的位置把句子分成三个部分,分别池化,再把三个部分的向量结合起来,做整个句子的向量化表示。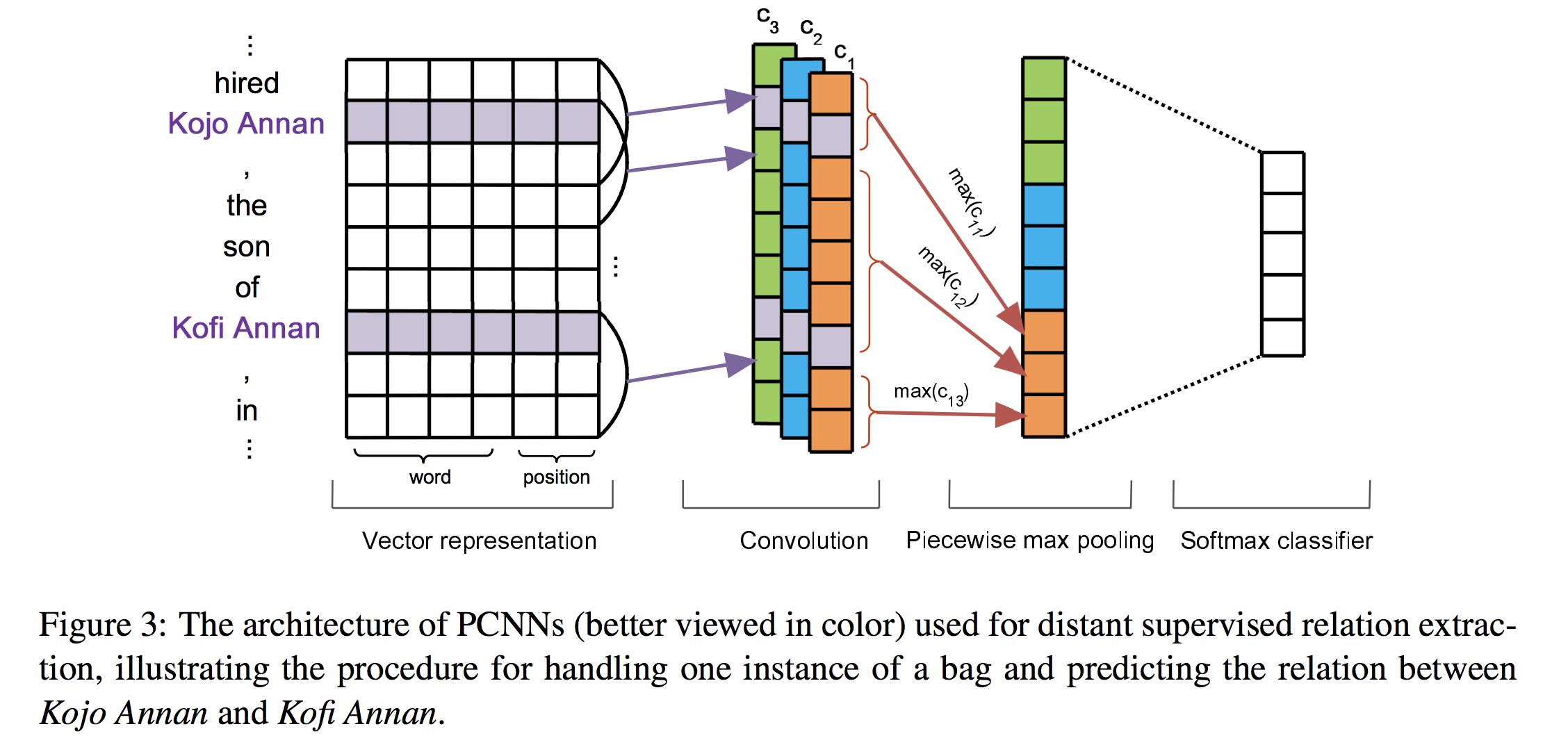
后面还讲了开放域更复杂的事件抽取,像是缺少触发词,可以通过从一堆要素中定位核心要素,用核心要素到句子当中找到触发词,将触发词和前面的要素关联到一起,再回标,然后在文本当中找到更多数据。
秦兵 - 机器智能中的情感计算
分享了文本情感计算的六个维度:
- 情感分类
面向评价对象的情感分类(aspect-based sentiment analysis)比较典型的还是利用上下文信息,采用注意力机制,使某个评价对象和词语进行更好的搭配,然后分类 - 隐式情感
不含情感词的情感表达(即隐式情感)在情感表达中约占 20%-30%,类型有事实型、比喻型、反问型等,事实型情感占多数,比如住酒店时说“桌子上有一层灰”,实际表达的就是不满。要判断这种情感需要依赖上下文,如 “桌子上有一层灰“ 后面一句是 ”我很不高兴”,就可以把 “桌子上有一层灰” 定义为贬义。找不到上下文可以考虑跨文档,在其他文档中找与之类似的句子再判定情感
同时,这类情感的计算通常也需要借助外部知识如隐式情感语料库等,尤其是修辞型的隐式情感,比如隐喻,可以借助隐喻语料库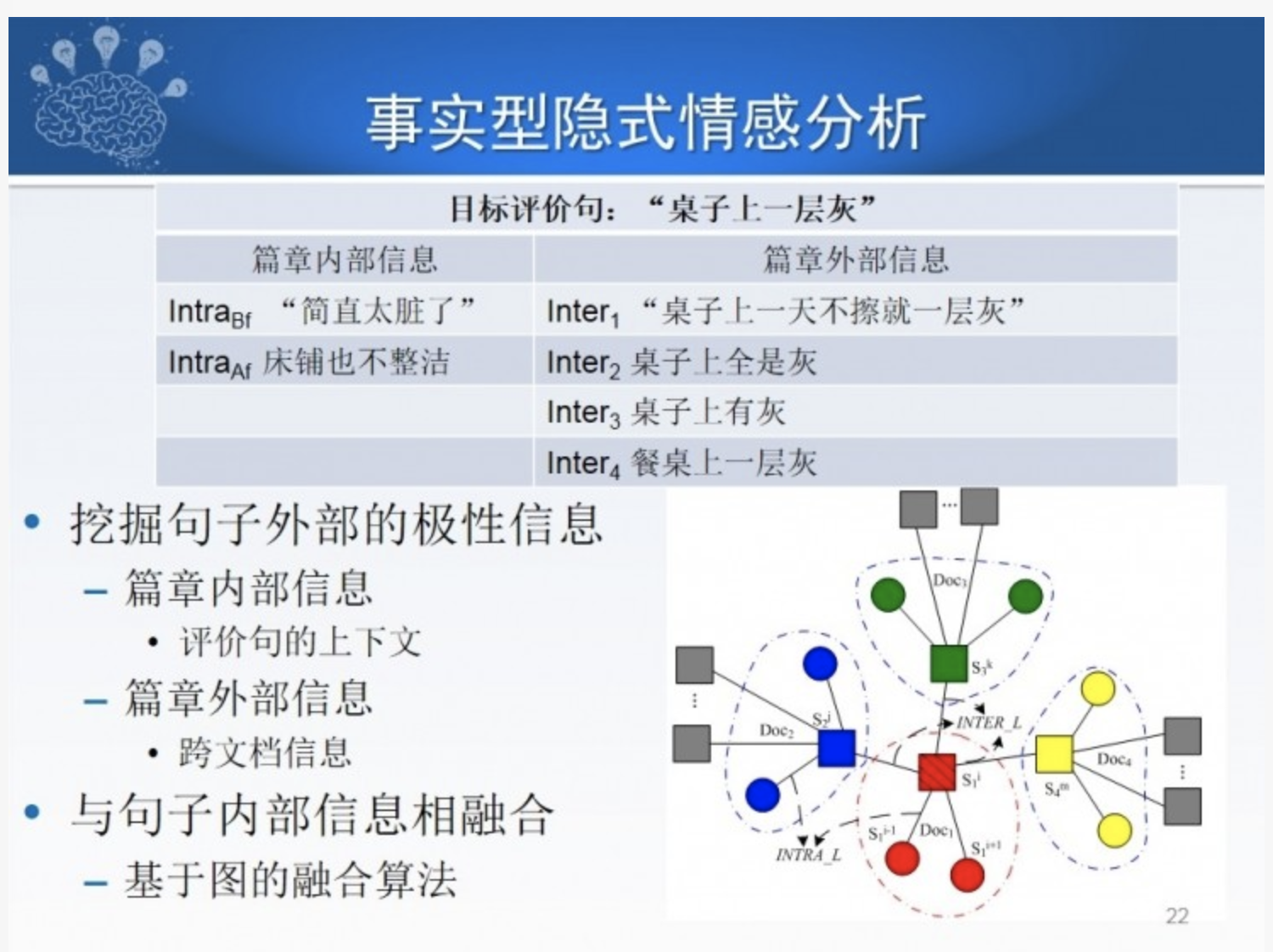
- 情感溯因
类似问答系统,有情感词、有原文,可以通过记忆网络判别哪句话是原因 - 个性化
在情感计算中加入用户特征/用户画像信息,包括自然属性、社会属性、兴趣属性、心理属性等,融入到已有的神经网络模型,来做情感分类 - 跨领域
利用领域无关词和领域相关词的链接关系,分别进行聚类;
通过神经网络的隐层参数提取与情感相关、但与领域无关的词的特征来分类 - 情感生成
根据指定的情感类别生成情感表达,应用如产品评论生成、聊天系统、对情感表达进行情感极性变换、润色等
还有一个有意思的应用是中考、高考时经常看到的诗词鉴赏。
钟黎 - 从 0 到1 打造下一代智能对话引擎
这个和之前的项目/工作经验高度相关,感觉更像是梳理了一遍之前的工作~~
业界通用智能问答平台要解决的问答类型:
- 任务驱动型(Task Oriented Dialogue)
用户希望去完成一些任务,比如查天气、查汇率等,包括词槽填充、多轮会话、对话管理等 - 信息获取型(Information & Answers)
目前业界落地最多的一种问答系统类型,包括搜索、单轮对话,根据数据类型划分有下面几类- 结构化知识,比如 CommunityQA(eg., FAQ)和 KBQA
- 半结构化/非结构化知识,比如说 TableQA(表格),PassageQA(文档)
- 多模态、跨媒体问答,比如说 VQA,存在视频、音频问答的语料库
- 通用闲聊型(General Conversation)
基础会话,包括闲聊、情感联系、用户信息等,使对话系统更富于人性化
重点讲的是第二类,具体讲了两个部分,一是快速召回,二是深度匹配。
无监督-快速检索
提高快速召回(无监督的快速检索)的三种方案,基于词汇计数(Lexical term counting)、基于语言模型、基于向量化。

很多是信息检索的思路,在 信息检索专题类 的博客都有探讨过。
有监督-深度匹配
深度匹配的两类常用方法,Siamese 网络 和 基于交互矩阵的网络。
Siamese 网络的基本思路:两个输入用同一个编码器进行编码,然后做相似度的计算,特点是共享网络结构和参数;
基于交互矩阵的网络:除了最后的相关性度量,中间过程里两个输入的某些词也会有交互。
问句较短时/短文档时两类网络一般能打成平手,但对长文档而言,基于交互矩阵的网络就会有更好的表现。
再后面还讲了如何在非结构化文档里寻找信息和答案,具体应用是机器阅读理解(MRC),系列博客也有提到。
最后总结了下业界问答系统建设的一些心得:
- 要重视 Baseline。
- 尽早建立起整个流程的 pipeline。
- 没有免费午餐定理,不存在万能算法。
- 领域相关的数据准备、数据清洗非常重要。

